Evaluating Hybrid Human-AI Systems for Discovering Undeclared Foreign Key Relationships in Large-Scale Relational Databases
Built entirely in Python, evaluated on real open-source data.
Foreign keys are missing. Nobody notices until it's too late.
Foreign key relationships are the backbone of any relational database. They define how tables connect and depend on each other. In theory, these relationships are always documented. In practice, they often are not.
In enterprise environments, foreign key constraints are frequently dropped for performance reasons, lost during migrations, or simply never documented in legacy systems. The result is databases that nobody fully understands, where data integration and analysis become guesswork.
A database with 1,800 columns has over 3 million possible column pair combinations. Finding the meaningful ones manually is not realistic. My dissertation asked whether a system could do it automatically, at scale, with enough accuracy to be trusted.

Example of a real-world database with missing foreign key documentation
A six-step pipeline combining statistics, naming patterns, and human expertise.
I built a six-step pipeline that combines statistical analysis, naming pattern recognition, and human expertise to discover undeclared foreign key relationships automatically.
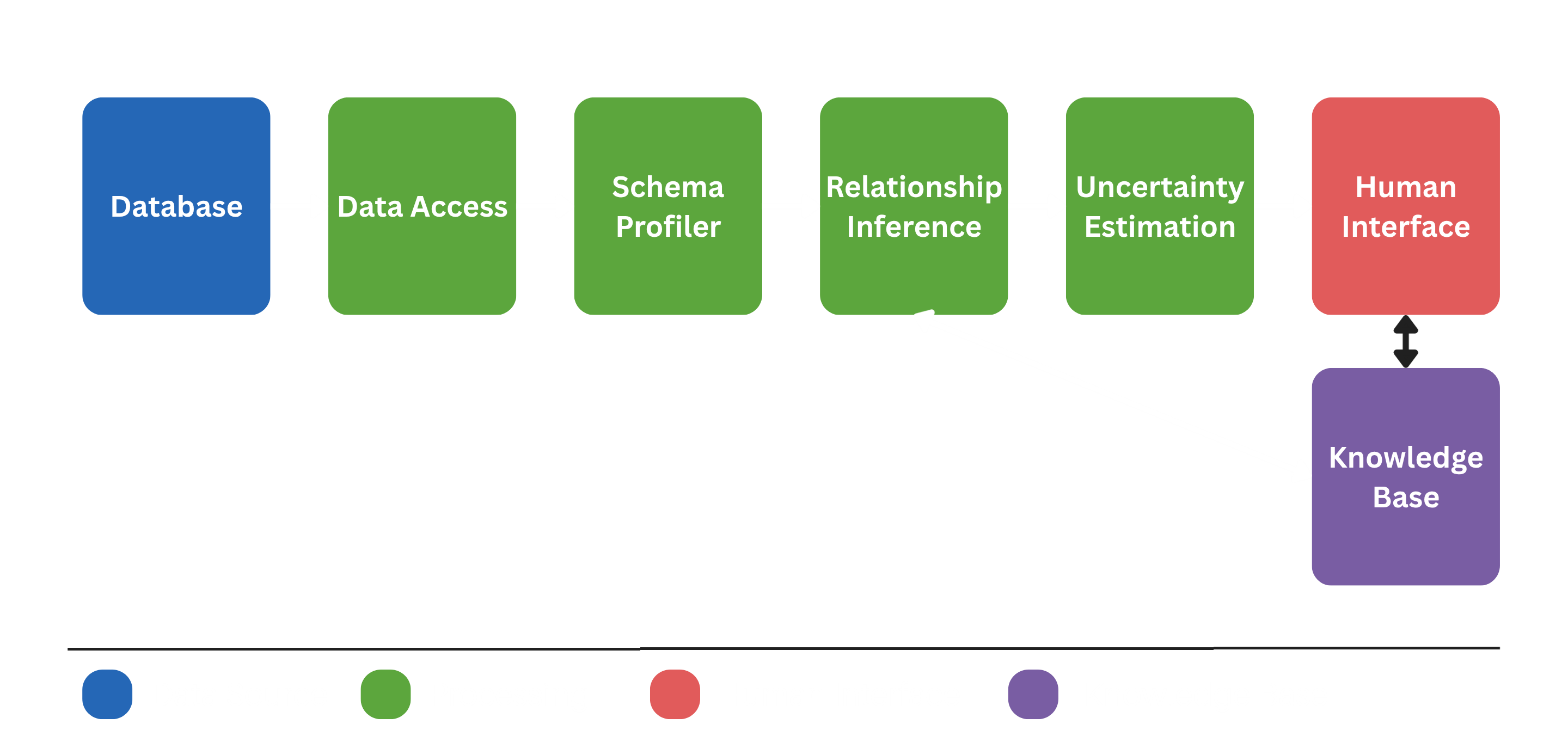
Figure 3.2: System Architecture Diagram
Every decision is explainable. No black boxes.
The centrepiece of the system is the human review interface. It is a CLI tool that presents uncertain candidates to a reviewer with full context: confidence score, signal breakdown, sample values from both columns side by side, and a plain-English explanation generated by GPT-4.
Reviewers are never shown a black box score. Every decision is fully explainable.
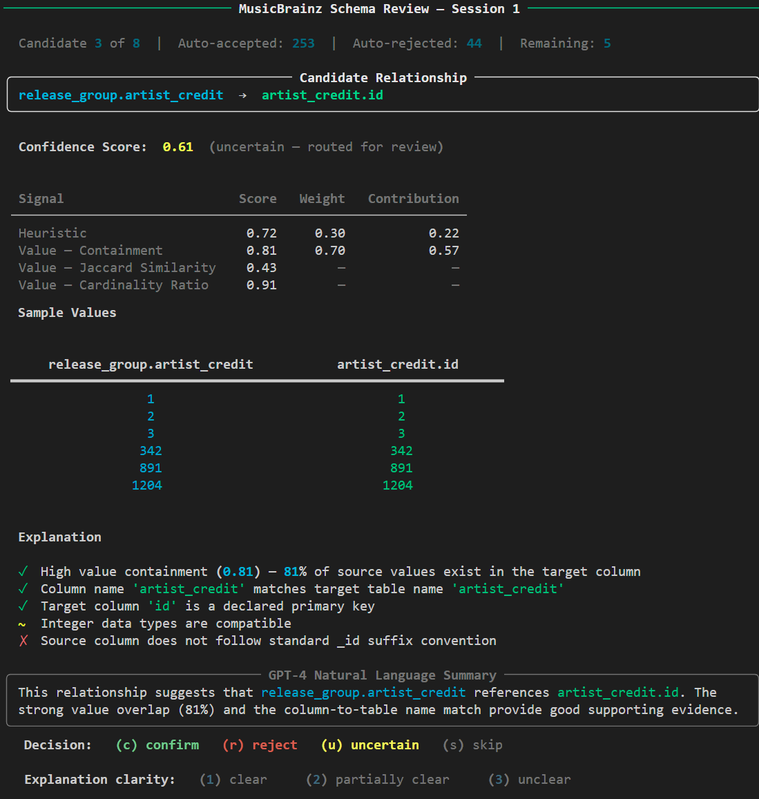
Human Review Interface: CLI screenshot
92.64% F1: over 15 percentage points above either signal alone.
The system was evaluated against 310 known foreign key relationships in MusicBrainz, a real open-source music database with 368 tables and 238 million rows.
Testing each component in isolation revealed how much each signal contributed:
| Configuration | F1 Score |
|---|---|
| Name matching only | 76.90% |
| Value analysis only | 78.61% |
| Combined (final system) | 92.64% |
Neither signal alone was sufficient. Combined, they produced a result over 15 percentage points higher than either individually.